Blog
Notes on what the Verbatim Index actually found, and what changes for you on Monday morning.
The Blind Taste Test Problem: Why Comparing AI Answers Isn't Checking Them

LinkedIn's Crosscheck hides the model names and asks which answer you prefer. The Pepsi Challenge already showed us what a blind taste test actually measures, and it isn't quality.
The One Verification Layer Frontier Labs Will Never Build

A rival lab's model tearing into an AI answer is one of the most effective checks there is. It's also the one no frontier lab will ever build, because it means letting a competitor judge their own output. Here's why it has to live between the labs.
The Anna Delvey Problem: When AI Answers Are Too Polished to Question

We have all been Anna Delveyed: trusting an AI answer because it reads confident, polished, and authoritative, only to find later that it doesn't hold up. Why the AI version is the harder con.
What Part of Your AI Workflow Is Responsible for Disagreement?
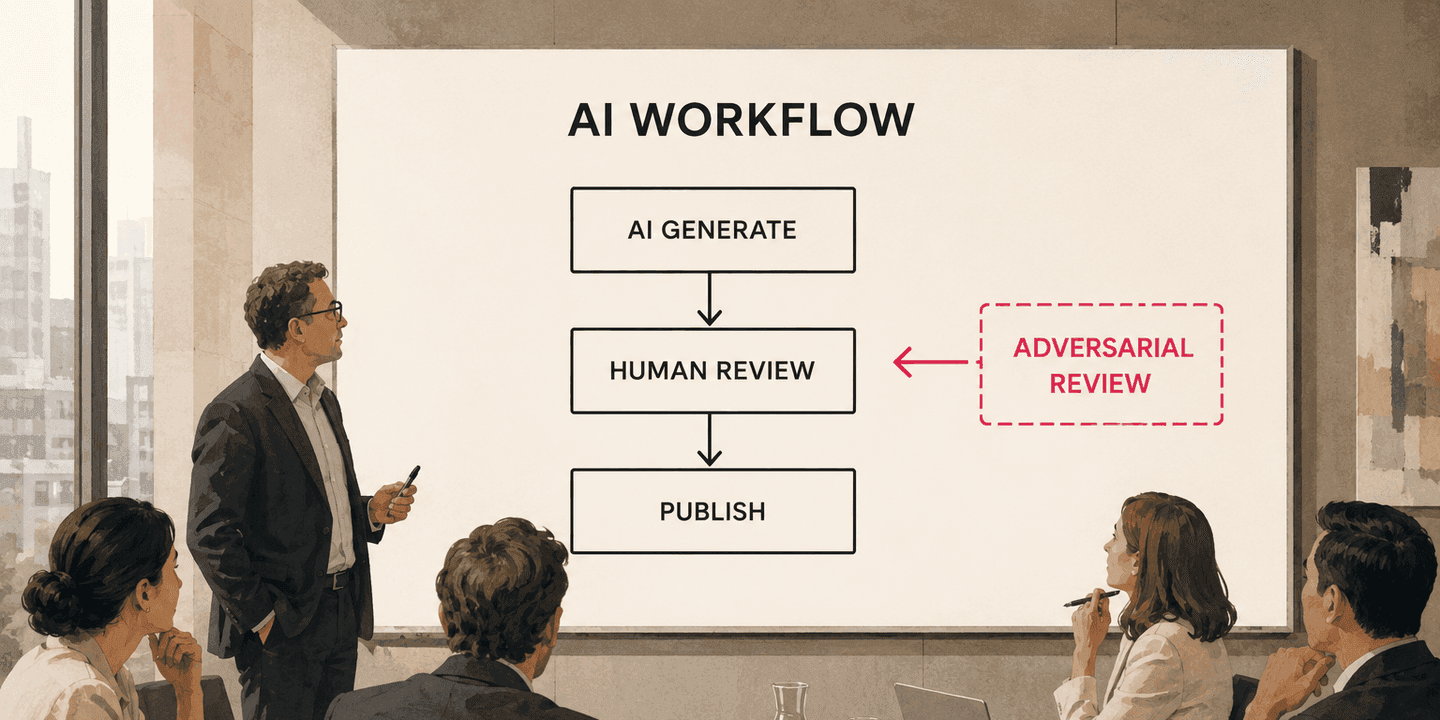
KPMG pulled a published AI report after named organizations disputed its claims. The failure wasn't competence. It was that AI produces work faster than any process was built to verify it.
Pope Leo XIV's Magnifica Humanitas Calls for AI Oversight. But Who Guards the Guardians?

Pope Leo XIV's first encyclical, Magnifica Humanitas, calls for oversight of AI. But oversight is itself power. The case for pluralism, and competing models that check each other, as the safeguard he left unnamed.
Nine AI Models Forecast AGI by 2030. Not One Put It Above a Coin Flip.

Anthropic argues self-improving AI is arriving fast. We forced nine frontier models to put a number on AGI by 2030, and not one gave it better than even odds. The disagreement was about the definition, not the date.
When Verbatim gets it wrong (and what that tells you)
A critique system that won't tell you when it can't see something is just confidence dressed up as rigor. What happened when we ran our own workflow message through Critique.
Will AGI Exist by 2030? We Ran 9 AI Models Through Adversarial Review to Find Out.

Seven of nine frontier AI models said AGI is primarily a compute problem. The two dissenters were both Anthropic models.
Which AI Is the Harshest Critic?
GPT-5.5 marked 39.78% of its cross-family verdicts as disputed across five Verbatim Index questions. Gemini 3.1 Pro Preview marked 25.28%. A 14.50-percentage-point spread.
Claude Opus Costs 7x More Than Gemini. It Ranked Lower Too.
On q-001 of the Verbatim Index, Anthropic's Opus retrieved zero web tokens and was disputed by cross-vendor critics 1.32 points more often than Sonnet 4.6.
Perplexity vs. Verbatim: When to Compare AI Answers vs. Audit One
Perplexity Max's Model Council runs your query through three models in parallel. Verbatim's Council audits the answer you already have. Query-anchored versus output-anchored.
Web Search Doesn't Make AI Answers More Trustworthy
Only four of nine models in this Verbatim Index run had usable retrieval telemetry. Inside that four, the ranking aligned on the top pair and inverted on the bottom.